


In our previous post, we talked about creating an AI agent for technical communities that can use the conversation history amongst colleagues and other members to answer the user’s common questions. InSightful is the agent we built that uses the Reasoning and Action (ReAct) approach to respond to user queries accurately. However, during the retrieval process the generalization of the retrieved information causes the agent to provide a high-level overview of the information. You can greatly improve the results of the retrieved information from the conversation history within a community by retrieving relevant specific information according to a query. This can be achieved with a reranker.
In this blog post, we will explore rerankers, types of rerankers, selecting an appropriate reranker for your project, and implementing it in an existing application to improve the Retrieval- Augmented Generation (RAG) framework.
What are rerankers?
Rerankers are models used to “rerank” retrieved information based on its relevance to a user’s query. After a base retriever model retrieves information from a data source, this information is passed to the reranker model. The reranker then evaluates and prioritizes the most relevant pieces of information according to the user’s query. This process significantly enhances the quality of the Agent’s generated response by ensuring that it utilizes the most pertinent information retrieved in relation to the user’s question.
How do rerankers work?
An embedding model converts text and information into numerical data that can be understood and processed by a Large Language Model (LLM). It places the tokenized text into vectors, enabling vector operations. These embeddings allow the LLM to augment its responses with retrieved information, powering the Retrieval-Augmented Generation (RAG) framework.
Rerankers are built on top of embeddings. They take the retrieved embeddings, obtained through similarity search or maximum marginal relevance search, and prioritize the information based on relevance.
In other words, rerankers act as a “filter” on top of embeddings. Their singular aim is to determine the most relevant information by performing their own similarity search or maximum marginal relevance search on the retrieved embeddings.
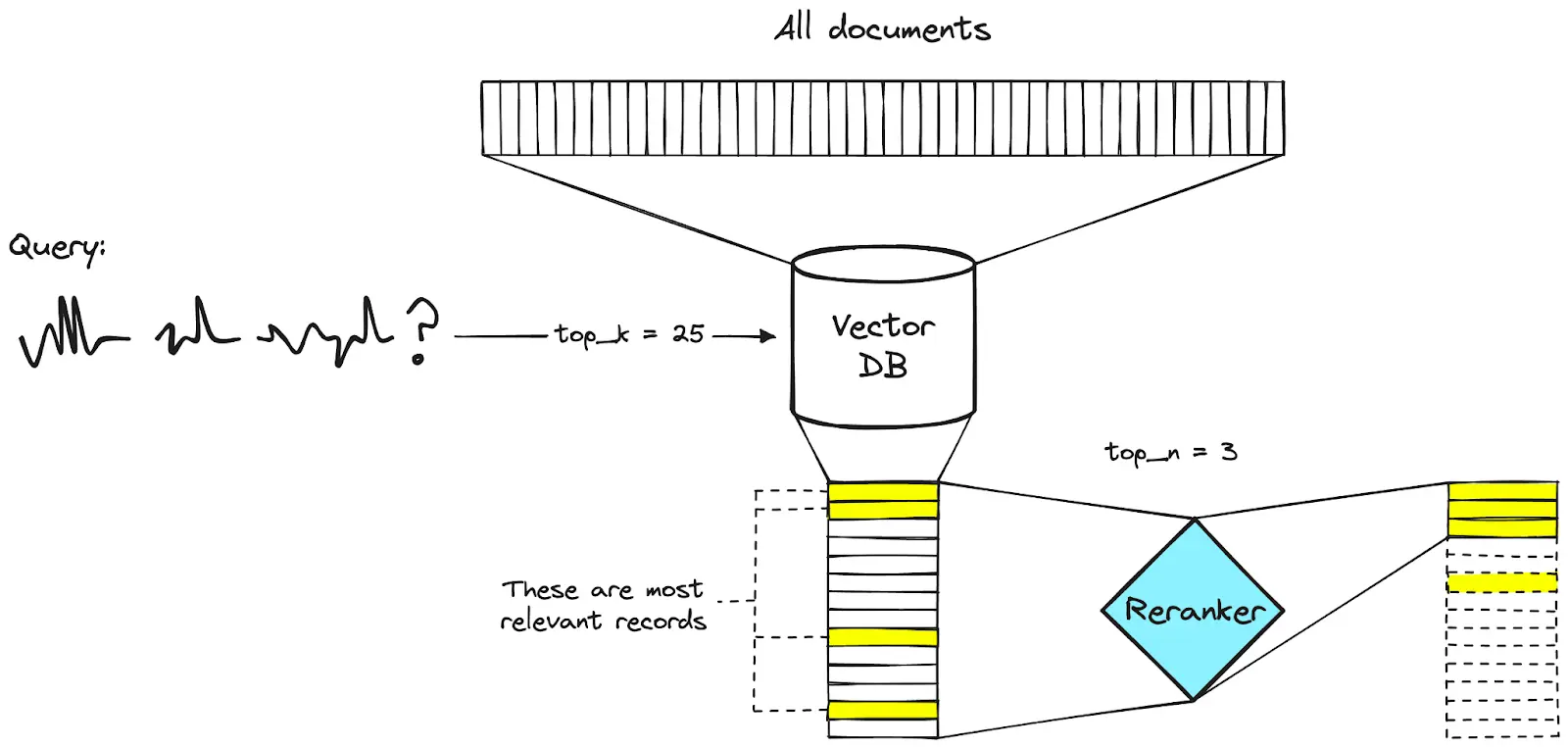
Considerations when selecting rerankers
There are several factors that you should consider when selecting a reranker, such as your use case, nature of data, and performance characteristics you require. Regardless of these factors, you must be sure to check off certain criteria before proceeding with a said reranker model, here are some to keep in mind:
Relevance: Determine the level of precision needed in the retrieval tasks.
Latency: Consider how quickly you want the reranker to produce results. This is especially important in production environments where mission critical tasks are of utmost importance.
Scalability: Analyze if the reranker can handle the existing and expected volume of data, number of users and frequency of queries.
Integration: The selected reranker should be able to integrate with the existing systems and workflows.
With these considerations in mind, let’s explore the different types of rerankers.
Types of rerankers
Primarily, there are 3 types of rerankers:
BERT-based: These rerankers utilize the BERT model to rerank embeddings. BERT’s bidirectional nature allows for a deep contextual understanding of the text, improving the relevance of search results by considering the context of both the query and the document.
Cross-Encoder: Cross-encoders handle the document and query together, encoding them simultaneously. This method allows for a more integrated and nuanced understanding of their relationship, which can significantly enhance the precision of relevance scoring. The joint encoding process enables the model to directly learn and evaluate the interactions between the query and document, providing a high level of accuracy in reranking.
Bi-Encoder: Bi-encoders handle the document and query separately, making them more suitable for large datasets and real-time applications. They independently generate embeddings for the query and document, which are then compared using a similarity metric such as cosine similarity. This approach allows for efficient retrieval and scalability.
The Cross-Encoder and Bi-Encoder also use BERT to encode the document, however, the approach for each of these is different. Here’s a diagram to reinforce these concepts:
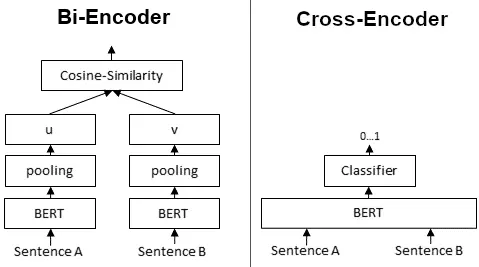
(Difference Between Bi-Encoder and Cross-Encoder)
Choosing a reranker: BERT-based vs Cross-Encoder vs Bi-Encoder
As we’ve discussed the types of rerankers, let’s see how we choose the best reranker for our use case. For this, we’ll break down the pros and cons of each type to make the decision easier.
| Reranker Type | Pros | Cons | Best Use Cases |
| BERT-based Rerankers | Deep contextual understanding: BERT’s bidirectional nature allows it to capture the context of words within a sentence, leading to highly accurate relevance scoring. |
Fine-Tuning capability: These models can be fine-tuned on specific datasets to improve performance on particular tasks. | Computationally intensive: BERT models are large and require significant compute resources for training and inference.
High latency: They suffer from high latency, making them unsuitable for real-time applications such as recommendation systems and search engines. | Enterprise search: Retrieval of the most relevant internal documents, emails, and reports where precision is critical, and immediate results are not necessary.
Academic research: Finding the most pertinent academic papers and articles from large databases. |
| Cross-Encoders | High precision: By jointly encoding the query and document, cross-encoders capture detailed interactions and provide high relevance precision.
Effective contextual understanding: They excel at understanding the complex relationships between the query and document, leading to more accurate relevance assessments. | High latency: Processing each query-document pair together is computationally expensive and time-consuming.
Scalability issues: Not ideal for large-scale or real-time applications due to the intensive computational requirements. | Question Answering systems: Providing precise and contextually appropriate answers to user queries.
Legal and Medical document retrieval: Retrieving the most relevant guidelines, research papers, and legal documents where detailed understanding is crucial. |
| Bi-Encoders | Efficiency: Embeddings can be precomputed, allowing for fast retrieval and ranking.
Scalability: Suitable for large datasets and real-time applications due to lower computational requirements. | Potential precision trade-off: May not capture the intricate interactions between the query and document as effectively as cross-encoders, potentially leading to slightly lower precision. | Real-Time applications: Search engines, chatbots, and recommendation systems where quick responses are essential.
Large-Scale retrieval: Scenarios involving large datasets where efficiency and scalability are crucial. |
By understanding the strengths and weaknesses of each type of reranker, you can choose the best one for your specific use case, balancing the trade-offs between precision, efficiency, and scalability. This approach ensures that your information retrieval system is optimized for the task at hand, providing the best possible user experience.
Open source vs closed source reranker models
With the increasing advocacy for open source AI technologies, there are numerous reranker models being developed and open-sourced online. For example, platforms like HuggingFace host a growing number of models in various fields of AI. Conversely, some companies have developed proprietary models and offer limited developer access through APIs. Notable companies include Anthropic, OpenAI, and NVIDIA.
Open source rerankers provide transparency and accessibility as their source code is available for inspection, modification, and improvement, fostering trust and community contributions. However, they can be resource-intensive, requiring significant computational resources and ongoing maintenance.
Closed-source rerankers, on the other hand, are known for high performance due to optimized models and advanced features resulting from extensive research and development. They offer reliability and support through dedicated customer service and Service Level Agreements (SLAs), ensuring prompt issue resolution and uptime guarantees. However, they come with significant costs, including usage fees and subscription costs, and lack transparency, as the inner workings are not available for inspection.
Ultimately, the two choices boil down to this:
Open source rerankers offer flexibility, cost-effectiveness, and transparency, making them ideal for those with the necessary technical expertise and infrastructure.
Closed-source rerankers, on the other hand, provide high performance, reliability, and ease of use, which are critical for enterprise applications requiring robust support and scalability.
Implementing a reranker in an existing application
Let’s now move on to the more practical aspects of a reranker and see it in action. Before jumping into the code and demo, let’s see a comparison between a reranker workflow and a non-reranker workflow:
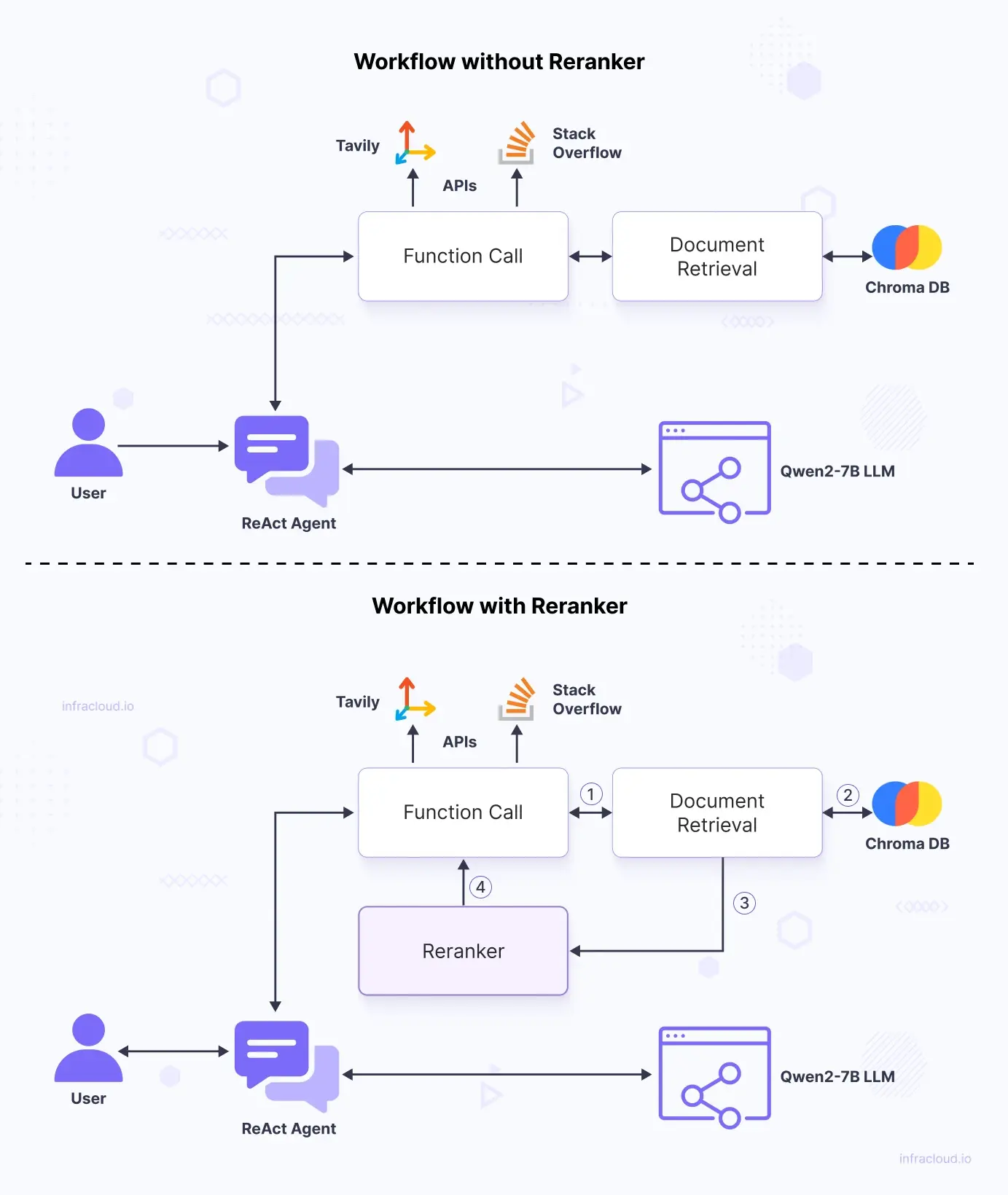
For clarity, the new sub-workflow of the reranker is numbered. The reranker ranks the documents after the documents are retrieved by the document retriever and returns it back to the function call which is then passed to the agent to generate its response.
def create_reranker_retriever(name, model, description, client, chroma_embedding_function, embedder):
rag = RAG(llm=model, embeddings=embedder, collection_name="Slack", db_client=client)
pages = rag.load_documents("spencer/software_slacks", num_docs=100)
chunks = rag.chunk_doc(pages)
vector_store = rag.insert_embeddings(chunks, chroma_embedding_function, embedder)
compressor = TEIRerank(url="http://{host}:{port}".format(host=os.getenv("RERANKER_HOST", "localhost"),
port=os.getenv("RERANKER_PORT", "8082")),
top_n=10,
batch_size=16)
retriever = vector_store.as_retriever(
search_type="similarity", search_kwargs={"k": 100}
)
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)
info_retriever = create_retriever_tool(compression_retriever, name, description)
return info_retriever
(Developing a reranker as a tool)
We start off with the usual RAG pipeline and create a retriever object of the vector store. The usage of vector store as a retriever is provided by LangChain. We developed our own RAG class and provide a set of standard arguments that are required for RAG. When we are loading the documents, we can specify the number of documents we want to download from the dataset. The dataset is a table with several rows, so the num_docs parameter specifies the number of rows to download in our case.
In essence, this code snippet describes how a reranker is initialized in LangChain. The regular retrieving process followed through until retriever, then we use this as a base retriever and use it with a reranker. A compressor is used to compress context, and our reranker achieves this while retaining the most relevant information in the context. With a blend of the base retriever and the reranker, we create a new retrieval tool that is fed to our agent.
TEI Rerank and LangChain
As of the time of writing, LangChain does not have an integration with the HuggingFace Text Embedding Inference (TEI) Server’s Rerank endpoint which caused us to write our own adapter to bring these two together. Here’s the link to our work for your reference: InSightful Reranker.
Performance of InSightful with and without reranker
Let’s now look at the demo of InSightful’s performance. Observe the quality of response between the approaches.
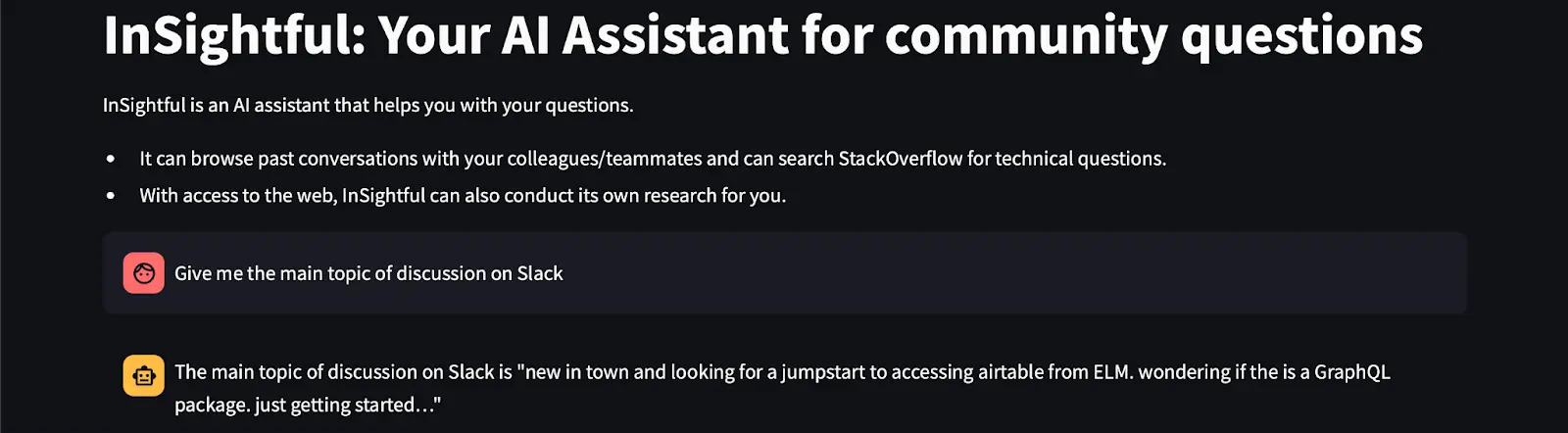

As you can see, the reranker provides a more precise answer, using an actual message sent by a participant in the conversation to generate its response. On the other hand, not using a reranker provides a high-level overview of the general discussion on. As the amount of information increases, the reranker will do a better job at providing concise and accurate information according to the user’s query.
Conclusion
In this blog post, we demystified rerankers and stripped it down to the very fundamentals. The references section has additional primers that you may find useful to understand rerankers. We hope that you can use this article as a guide that you can always come back to when you want to use a reranker for your own applications. With the provided code repo, you may also use it as a template and create your own versions. However, having an efficient and scalable cloud infrastructure is crucial for building an AI application. AI & GPU Cloud experts can help you achieve this.
We hope you found this article as useful as intended. If you have any feedback, suggestions, or questions, please feel free to reach out to Shreyas on LinkedIn.