


In the fast-paced world of DevOps, the GitOps methodology coupled with tools like Argo CD has emerged as powerful tools that streamline the development process. GitOps, a modern approach to continuous delivery and deployment, leverages Git as the source of truth for managing infrastructure and applications. Argo CD, on the other hand, is a versatile GitOps tool that streamlines the deployment process, ensuring applications are always in the desired state.
Argo CD can work with most standard Kubernetes resources such as Deployments, Services, ConfigMaps, Secrets, CRD’s etc. It also deploys and manages Kubernetes jobs just as all other types of resources. Kubernetes Jobs play a vital role in managing batch processes and ensuring their successful execution within a Kubernetes cluster. Jobs ensure that a specified number of pods successfully complete their tasks before terminating. Argo CD, provides a streamlined approach to manage, automate, and monitor these Jobs.
In this blog post, we will explore the integration of GitOps and Argo CD for managing Kubernetes jobs. We will look into the difficulties of integrating jobs with Argo CD. We’ll explore the potential stumbling blocks and provide practical solutions for maintaining a seamless workflow. We will also discuss Argo CD hooks and hook deletion policy. By the end of this read, you’ll be equipped with the knowledge to navigate these potential pitfalls.
Problem Statement
In a recent operational scenario, one of our Argo CD enterprise support customers faced a situation where they encountered a specific challenge related to updating an existing Kubernetes job designed for database migration. They have implemented Argo CD as a chosen tool to effectively synchronize their Git repository, which encompasses critical yaml configurations for Kubernetes jobs, among other resources, with the Kubernetes cluster. Despite their attempts to make the necessary modifications in the Git repository, they found the process to be unexpectedly complex.
Upon initial deployment, the job was successfully created and executed in precise accordance with the expectations. However, subsequent attempts to refine the job’s definition YAML within the repository yielded unexpected results. Unfortunately, Argo CD failed to recognize and apply these modifications, leaving them with an unanticipated roadblock in the database migration process.
When our engineers started looking into this problem, we first checked the controller logs. It seemed that the error was produced while replacing the Kubernetes job.
kubectl logs argocd-application-controller-0 -n argocd
time="2023T04:23:57Z" level=info msg="Updating operation state. phase: Running -> Failed,
message: 'one or more tasks are running' -> 'one or more objects failed to apply, reason: error
when replacing \"/dev/shm/3711963105\": Job.batch \"test-job\" is invalid: [spec.selector:
Required value, spec.template.metadata.labels: Invalid value: map[string]string(nil): `selector`
does not match template `labels`, spec.selector: Invalid value: \"null\": field is immutable,
spec.template: Invalid value: core.PodTemplateSpec{ObjectMeta:v1.ObjectMeta{Name:\"\", GenerateName:\"\", Namespace:\"\", SelfLink:\"\", UID:\"\", ResourceVersion:\"\", TopologySpreadConstraints:[]core.TopologySpreadConstraint(nil), OS:(*core.PodOS)(nil)}}:
field is immutable]'" application=argocd/test-job syncId=00004-VTale
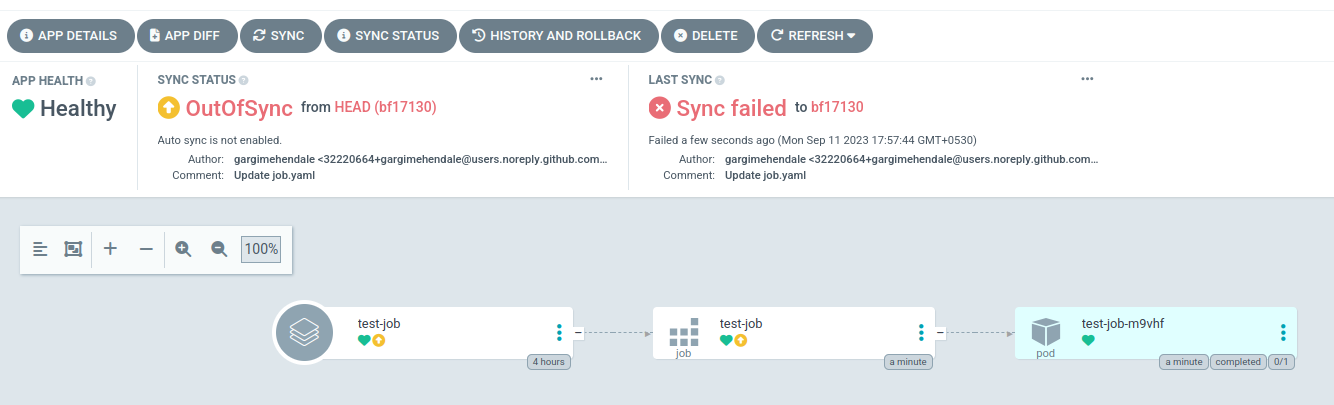
(In the screenshot, you can see the ‘OutOfSync’ status for the application caused due to the error. It led us to further troubleshoot the issue.)
Troubleshooting
As the first step of troubleshooting, we checked the application details for the exact error.
argocd app get test-job
The application produced the following error while syncing it.
Job.batch "test-job" is invalid:
[ spec.selector: Required value,
spec.template.metadata.labels:
Invalid value: map[string]string(nil): `selector` does not match template `labels`,
spec.selector: Invalid value: "null": field is immutable
]
We tried using the replace=true in the sync option of the application and tried to sync it again.
syncPolicy:
syncOptions:
- Replace=true
argocd app sync job-test
However it was not able to resolve the issue and produced the same error. The error was caused as some fields in job specifications are immutable.
Kubernetes jobs are classical one-time events. Due to this, lots of fields in the Job specifications are immutable and can’t be changed once the resource exists in your cluster.
Solution
We can see that due to the immutability of the fields, a job cannot be updated. If fields cannot be updated, then the only way to update a job is to delete the job before re-creating it. This is where Argo CD sync hooks come into the picture.
Argo CD hooks are one of the popular features provided by Argo CD. Hooks are basically scripts or commands that are executed in a deployment lifecycle at some specific points. These hooks enable you to customize the deployment process by adding your own logic which can be useful for performing tasks like running tests, database migrations, or executing custom scripts before or after a deployment.
Here are some types of Argo CD hooks:
PreSync Hooks: PreSync hooks are executed before any sync operation starts, prior to the application of the manifests. They can be used to perform tasks like environment validation, or custom operations before deploying the resources.
metadata: annotations: argocd.argoproj.io/hook: PreSyncSync Hooks: Sync Hooks are executed during the sync operation simultaneously with the application of manifest. They run after all the PreSync hooks are successfully completed. They allow you to run custom scripts or commands after the resources have been deployed but before the sync operation is considered complete.
metadata: annotations: argocd.argoproj.io/hook: SyncSyncFail Hooks: SyncFail Hooks are executed when a sync operation fails. They are used to perform cleanup operations or other tasks in response to a failed deployment.
metadata: annotations: argocd.argoproj.io/hook: SyncFailPostSync Hooks: PostSync hooks are executed after a sync operation is complete and resources are in a healthy state. They can be used for tasks like sending notifications, updating external systems, running health checks after a deployment, etc.
metadata: annotations: argocd.argoproj.io/hook: PostSync
We can use appropriate hook annotation in our application as per the requirements. Particularly, in our scenario, we need to delete the existing kubernetes job so a new job can be created, this is where the hook deletion policy comes into picture. We can use different deletion policies as per the requirements.
Hook Deletion Policies
In Argo CD, the “hook deletion policy” is a feature that allows you to control what happens to hooks when a resource is deleted. Hooks can be deleted automatically by using the annotation: argocd.argoproj.io/hook-delete-policy.
You can also delete the hooks after a successful/unsuccessful run. Following policies will define when the hooks will be deleted.
HookSucceeded - The resource will be deleted after it has succeeded.
HookFailed - The resource will be deleted if it has failed.
BeforeHookCreation - The resource will be deleted before a new one is created (when a new sync is triggered).
You can apply these with the argocd.argoproj.io/hook-delete-policy annotation.
metadata:
annotations:
argocd.argoproj.io/hook: PostSync
argocd.argoproj.io/hook-delete-policy: HookSucceeded
We can use the appropriate deletion policy to delete the hooks as per the requirements. There can be one more solution we can use for this type of scenario, instead of resource hooks and deletion policy is the use of generateName parameter.
Generate Name
In Argo CD, a generate name is used to name the hooks using specified prefixes. Named hooks (i.e. ones with /metadata/name) are only created once. If you want a hook to be recreated each time, either use BeforeHookCreation policy or /metadata/generateName.
apiVersion: batch/v1
kind: Job
metadata:
generateName: integration-test-
annotations:
argocd.argoproj.io/hook: PostSync
Scenario 1: Use generateName parameter
This was the scenario faced by one of our customers where they were using a standalone Kubernetes job that was used for database migration. This job needs to be re-run whenever the image name is updated in the source repo. Standalone jobs can be run alongside your application deployment or perform some other tasks like syncing the docker secrets, performing some custom ad-hoc tasks, custom initialization tasks, cleanup tasks, data synchronization tasks, etc. These Jobs are not part of the Argo CD application definition, hence, are not synced, observed, or managed by Argo CD like other resources. They need to be operated manually. For this, one of the ways is to use the generateName parameter. Every time the application is synced it will spin up a new job with a new name. Here I have created a sample manifest with sleep command.
Prerequisites:
Argo CD should be installed in your cluster.
Steps:
Create an Argo CD application.
apiVersion: argoproj.io/v1alpha1 kind: Application metadata: name: standalone-job spec: destination: name: '' namespace: default server: 'https://kubernetes.default.svc' source: path: standalone-job repoURL: 'https://github.com/infracloudio/kubernetes-job-with-argocd' targetRevision: HEAD sources: [] project: default syncPolicy: syncOptions: - Replace=trueYou can sync the application using CLI.
argocd app sync argocd/standalone-job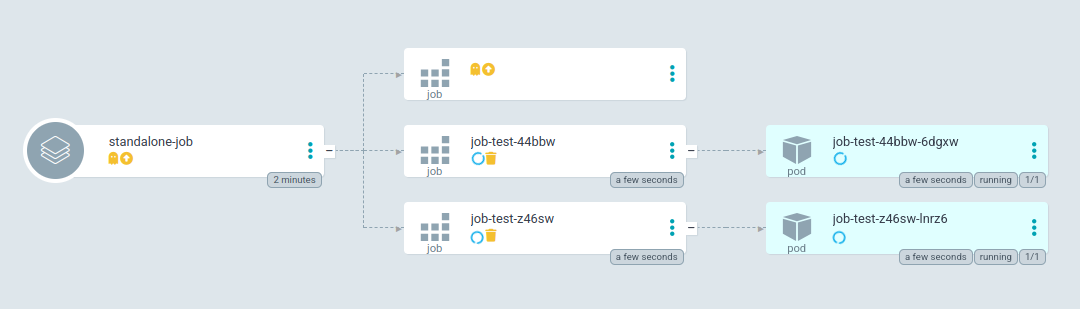
(You can see that a new job is created with a new name on every sync.)
Scenario 2: Use resource hooks with hook deletion policy
There can be another scenario where we have a Kubernetes job running with a pod resource. Whenever the pod image is changed, the job is automatically triggered, unlike standalone jobs. Another way to manage Kubernetes jobs is to use the Sync annotation in the manifest and hook deletion policy as BeforeHookCreation. With this, every time Argo CD syncs the job, it will delete the existing job and then create a new one. The steps for the same are shown below.
Prerequisites:
Argo CD should be installed in your cluster.
Steps:
Create an Argo CD application
apiVersion: argoproj.io/v1alpha1 kind: Application metadata: name: test-job spec: destination: name: '' namespace: default server: 'https://kubernetes.default.svc' source: path: job-with-pod repoURL: 'https://github.com/infracloudio/kubernetes-job-with-argocd' targetRevision: HEAD project: default syncPolicy: automated: prune: true selfHeal: trueYou can see the job is created.
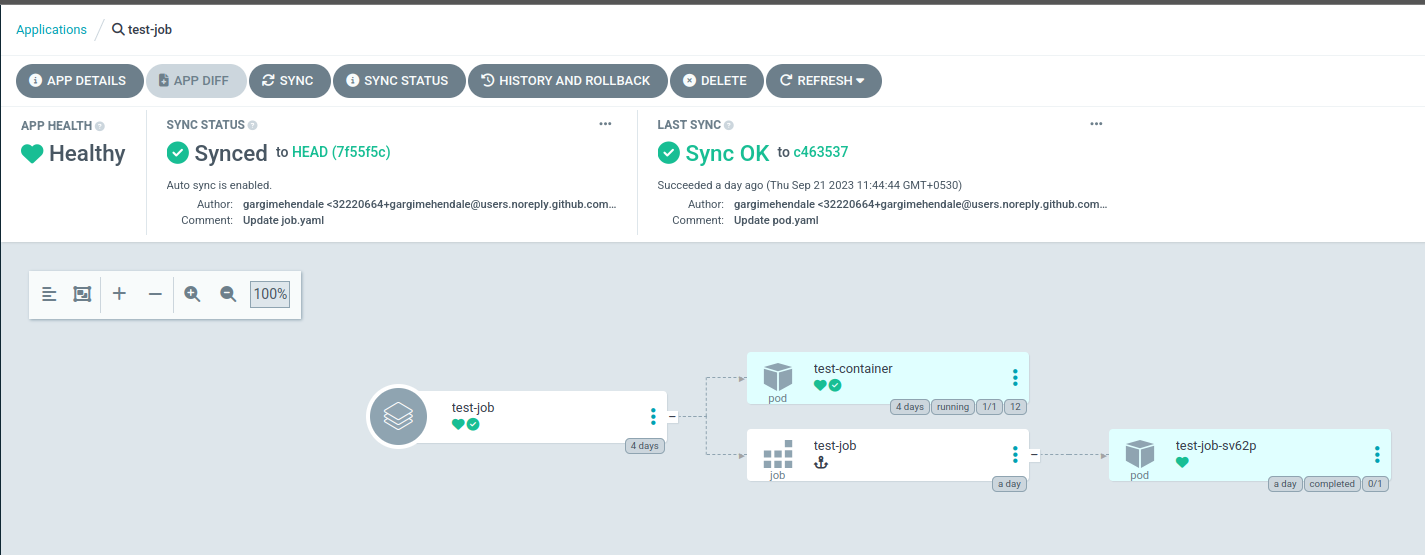
(Argo CD application status)
Make changes to the image name of a pod in the source repo.
spec: containers: - name: test-container image: nginxYou will see that the existing job is deleted and a new job with a new image name is created.

With the resolution of the immutable fields issue in Kubernetes jobs, we’ve not only overcome a synchronization hurdle in Argo CD but also gained a deeper understanding of effective job management. Through various scenarios, from standalone tasks to integrated jobs with other Kubernetes resources, we’ve explored the complexity of orchestrating tasks within clusters. The strategic application of tools like generateName and the careful consideration of hook deletion policies have emerged as powerful techniques for troubleshooting and optimizing deployments.
Conclusion
In this blog post, we’ve successfully tackled the challenge of immutable fields in Kubernetes jobs, which had been causing sync issues in Argo CD. We explored various scenarios for managing Kubernetes jobs with Argo CD, ranging from standalone jobs to jobs integrated with other Kubernetes resources. Along the way, we demonstrated the effective use of tools like generateName and hook deletion policies to troubleshoot potential issues.
I hope this post was helpful in resolving the issues you might have with the Kubernetes job synchronization. For more posts like this one, subscribe to our weekly newsletter. I’d love to hear your thoughts on this post, so do start a conversation on LinkedIn :)
Looking for help with GitOps adoption using Argo CD? Do check our Argo CD consulting capabilities and expertise to know how we can help with your GitOps adoption journey. If you’re looking for managed on-demand Argo CD support, check our support model.
References
Community Support
If you want to connect to the Argo CD community, please join CNCF Slack. You can join #argo-cd and many other channels too.